| 纯干货基于flinkcdc实现mysql到mysql/oracle/...... DML实时同步 | 您所在的位置:网站首页 › flink cdc oracle 异常后反复建立连接 › 纯干货基于flinkcdc实现mysql到mysql/oracle/...... DML实时同步 |
纯干货基于flinkcdc实现mysql到mysql/oracle/...... DML实时同步
|
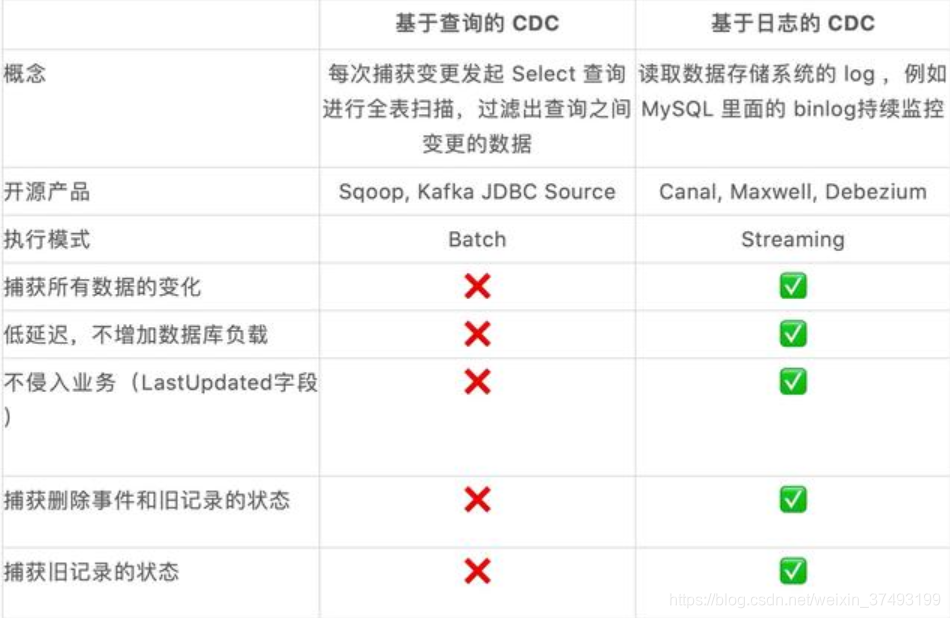
CDC 首先什么是CDC ?它是Change Data Capture的缩写,即变更数据捕捉的简称,使用CDC我们可以从数据库中获取已提交的更改并将这些更改发送到下游,供下游使用。这些变更可以包括INSERT,DELETE,UPDATE等操作。Flink SQL CDC 数据同步与原理解析 CDC 全称是 Change Data Capture ,它是一个比较广义的概念,只要能捕获变更的数据,我们都可以称为 CDC 。业界主要有基于查询的 CDC 和基于日志的 CDC ,可以从下面表格对比他们功能和差异点。
废话不多说,开始实战 一:基于自定义source和sink的方式 1.业务表与数据源示例 源库schema:amir 源表: 3.Source 和 Sink,此处sink以mysql示例 public class MySqlBinlogSourceExample { public static void main(String[] args) throws Exception { SourceFunction sourceFunction = MySqlSource.builder() .hostname("192.168.16.162") .port(3306) .databaseList("amir") // monitor all tables under inventory database .username("root") .password("123456") .deserializer(new JsonDebeziumDeserializationSchema()) .build(); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env .addSource(sourceFunction) .addSink(new MysqlSink()); env.execute("mysqlAmirToMysqlHmm"); } }4.自定义序列化类JsonDebeziumDeserializationSchema,序列化Debezium输出的数据 public class JsonDebeziumDeserializationSchema implements DebeziumDeserializationSchema { @Override public void deserialize(SourceRecord sourceRecord, Collector collector) throws Exception { HashMap hashMap = new HashMap(); String topic = sourceRecord.topic(); String[] split = topic.split("[.]"); String database = split[1]; String table = split[2]; hashMap.put("database",database); hashMap.put("table",table); //获取操作类型 Envelope.Operation operation = Envelope.operationFor(sourceRecord); //获取数据本身 Struct struct = (Struct)sourceRecord.value(); Struct after = struct.getStruct("after"); Struct before = struct.getStruct("before"); /* 1,同时存在 beforeStruct 跟 afterStruct数据的话,就代表是update的数据 2,只存在 beforeStruct 就是delete数据 3,只存在 afterStruct数据 就是insert数据 */ if (after != null) { //insert Schema schema = after.schema(); HashMap hm = new HashMap(); for (Field field : schema.fields()) { hm.put(field.name(), after.get(field.name())); } hashMap.put("data",hm); }else if (before !=null){ //delete Schema schema = before.schema(); HashMap hm = new HashMap(); for (Field field : schema.fields()) { hm.put(field.name(), before.get(field.name())); } hashMap.put("data",hm); }else if(before !=null && after !=null){ //update Schema schema = after.schema(); HashMap hm = new HashMap(); for (Field field : schema.fields()) { hm.put(field.name(), after.get(field.name())); } hashMap.put("data",hm); } String type = operation.toString().toLowerCase(); if ("create".equals(type)) { type = "insert"; }else if("delete".equals(type)) { type = "delete"; }else if("update".equals(type)) { type = "update"; } hashMap.put("type",type); Gson gson = new Gson(); collector.collect(gson.toJson(hashMap)); } @Override public TypeInformation getProducedType() { return BasicTypeInfo.STRING_TYPE_INFO; } }5.创建Sink,将数据变化存入mysql中,以insert、delete、update分别为例,如需要写入oracle、hdfs、hive、Clickhouse等,修改对应数据源连接信息 public class MysqlSink extends RichSinkFunction { Connection connection; PreparedStatement iStmt,dStmt,uStmt; private Connection getConnection() { Connection conn = null; try { Class.forName("com.mysql.cj.jdbc.Driver"); String url = "jdbc:mysql://192.168.16.162:3306/hmm?useSSL=false"; conn = DriverManager.getConnection(url,"root","123456"); } catch (Exception e) { e.printStackTrace(); } return conn; } @Override public void open(Configuration parameters) throws Exception { super.open(parameters); connection = getConnection(); String insertSql = "insert into amirtwo(ID,CRON) values (?,?)"; String deleteSql = "delete from amirtwo where ID=?"; String updateSql = "update amirtwo set CRON=? where ID=?"; iStmt = connection.prepareStatement(insertSql); dStmt = connection.prepareStatement(deleteSql); uStmt = connection.prepareStatement(updateSql); } // 每条记录插入时调用一次 public void invoke(String value, Context context) throws Exception { //{"database":"test","data":{"name":"jacky","description":"fffff","id":8},"type":"insert","table":"test_cdc"} //{"CRON":"7","canal_type":"insert","ID":"6","canal_ts":0,"canal_database":"amirone","pk_hashcode":0} Gson t = new Gson(); HashMap hs = t.fromJson(value, HashMap.class); String database = (String) hs.get("database"); String table = (String) hs.get("table"); String type = (String) hs.get("type"); if ("amir".equals(database) && "amirone".equals(table)) { if ("insert".equals(type)) { System.out.println("insert => " + value); LinkedTreeMap data = (LinkedTreeMap) hs.get("data"); String id = (String) data.get("ID"); String cron = (String) data.get("CRON"); iStmt.setString(1, id); iStmt.setString(2, cron); iStmt.executeUpdate(); }else if ("delete".equals(type)) { System.out.println("delete => " + value); LinkedTreeMap data = (LinkedTreeMap) hs.get("data"); String id = (String) data.get("ID"); dStmt.setString(1, id); dStmt.executeUpdate(); }else if ("update".equals(type)) { System.out.println("update => " + value); LinkedTreeMap data = (LinkedTreeMap) hs.get("data"); String id = (String) data.get("ID"); String cron = (String) data.get("CRON"); uStmt.setString(1, cron); uStmt.setString(2, id); uStmt.executeUpdate(); } } } @Override public void close() throws Exception { super.close(); if(iStmt != null) { iStmt.close(); } if(dStmt != null) { dStmt.close(); } if(uStmt != null) { uStmt.close(); } if(connection != null) { connection.close(); } } }6.运行MySqlBinlogSourceExample,查看source和sink source: 最终代码结构 |
 flinkCDC文档 flinkCDC:https://ververica.github.io/flink-cdc-connectors/release-2.0/ flink文档 flink1.13:https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/
flinkCDC文档 flinkCDC:https://ververica.github.io/flink-cdc-connectors/release-2.0/ flink文档 flink1.13:https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/ 目标schema:hmm 目标表:
目标schema:hmm 目标表: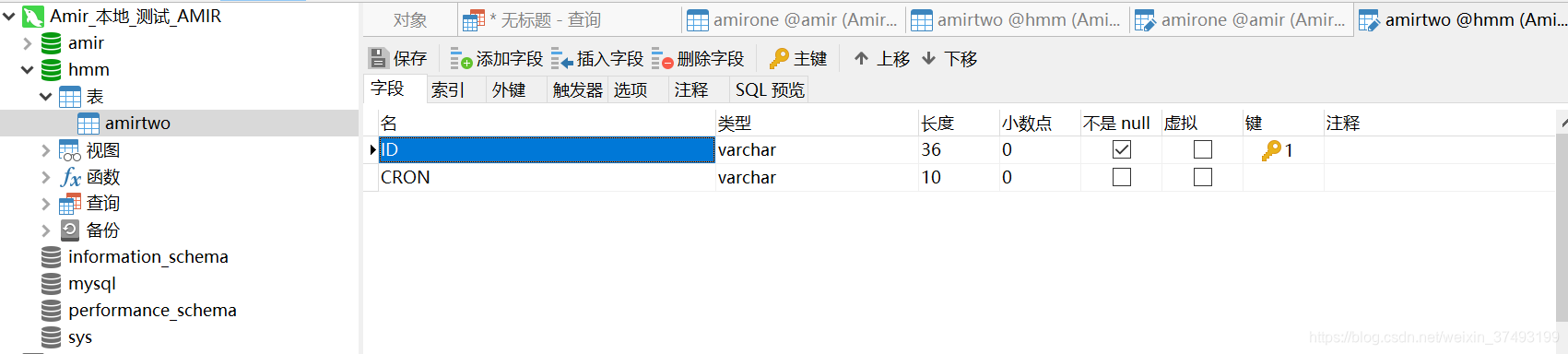 2.依赖如下
2.依赖如下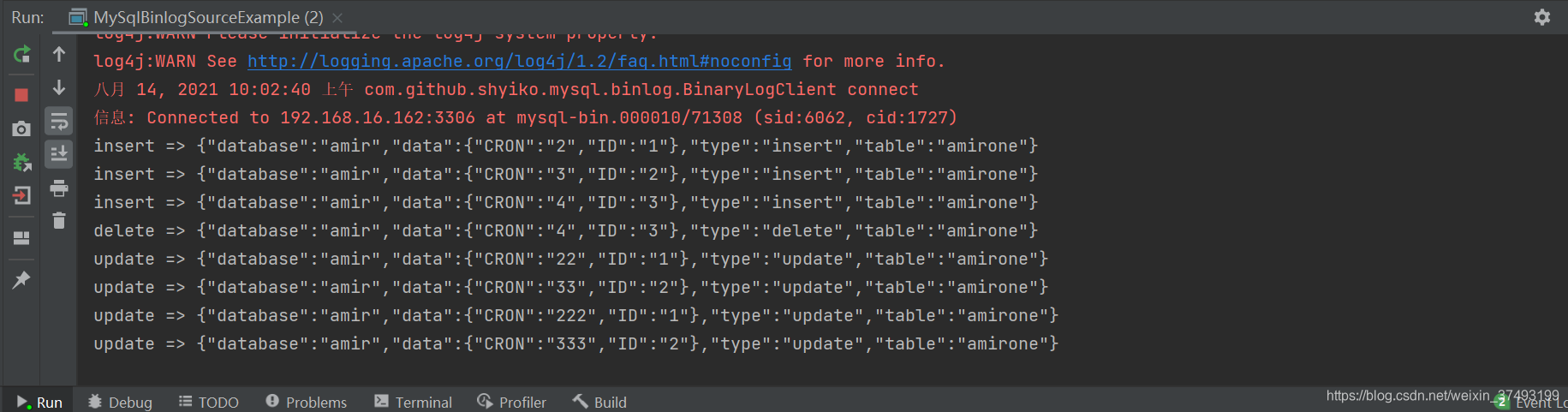 sink:插入3行,删除1行,更新4行,数据实时从A库业务表更新至B库业务表
sink:插入3行,删除1行,更新4行,数据实时从A库业务表更新至B库业务表 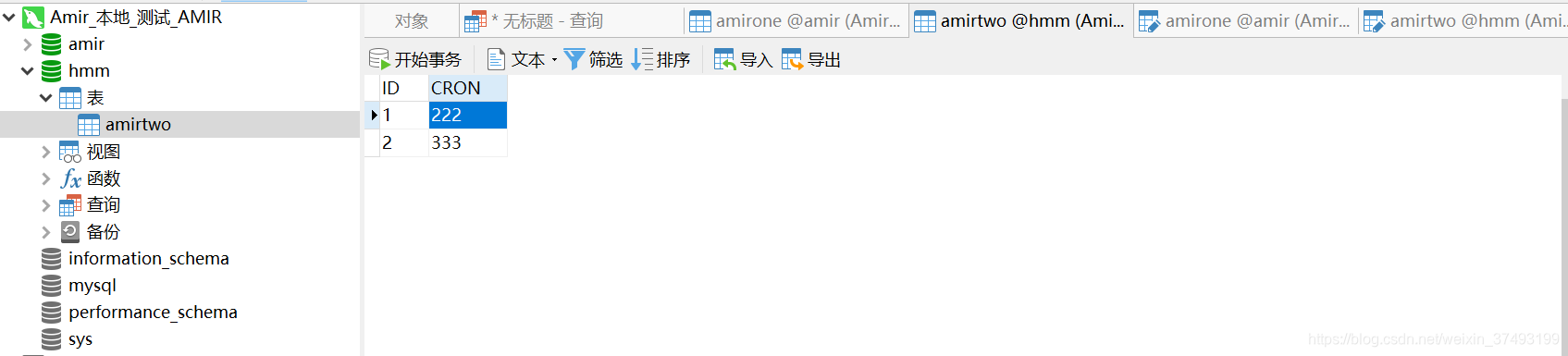 二:基于Flink SQL CDC,面向sql,简单易上手
二:基于Flink SQL CDC,面向sql,简单易上手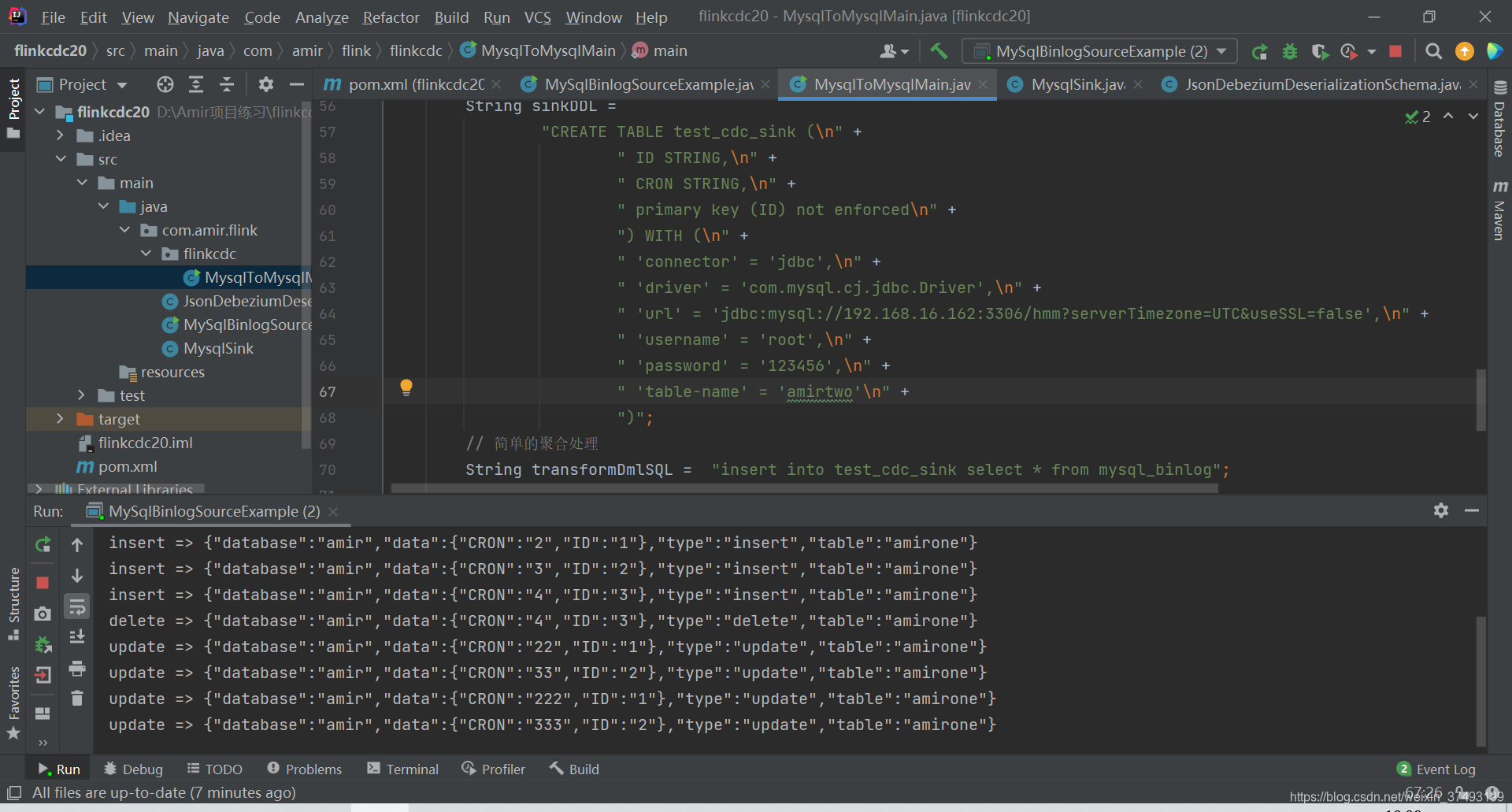 ending 逐梦,time will tell,yep!!!
ending 逐梦,time will tell,yep!!!【本文地址】
公司简介
联系我们